A Comprehensive Guide to Convolutional Neural Networks
In this article, we will explore Convolutional Neural Networks(CNNs), the fundamental architecture of CNNs, and understand how they work.
So Let’s Roll!!!

What are Convolutional Neural Networks?
Convolutional Neural networks(ConvNets or CNN) are a type of neural network inspired by how our brain processes visual information. CNNs are specifically designed for processing and analyzing visual data, such as images and videos. Some areas where CNNs are widely used are image segmentation, object detection, and face recognition.

Basic Architecture
The basic Architecture of CNNs comprises of three layers:
- Convolutional layer
- Pooling layer
- Fully-connected layer

Let’s delve into each of these layers to get a deeper understanding of their working:
1. Convolutional Layer
The convolutional layer is a fundamental component of CNNs. It is responsible for the convolutional operation, which involves applying a set of filters (i.e. Kernels) to the input data to extract patterns and features. This layer helps in identifying features, such as edges, textures, and shapes. This layer makes it easier for the neural network to recognize complex structures within images and videos.
These features are then combined to create a feature map which is then passed to the next layer for further preprocessing.
Key components of the Convolutional layer:
→ Input data
→ Filters
→ Feature map

Convolutional Operation:
- The convolution operation involves sliding a filter (i.e. kernel) over the input image, computing the dot product between the filter and the input, and then summing the results to produce a new feature map.
- This operation produces a new array called the feature map or activation map.
- This process is repeated for multiple filters, resulting in multiple feature maps, each capturing different features of the image.
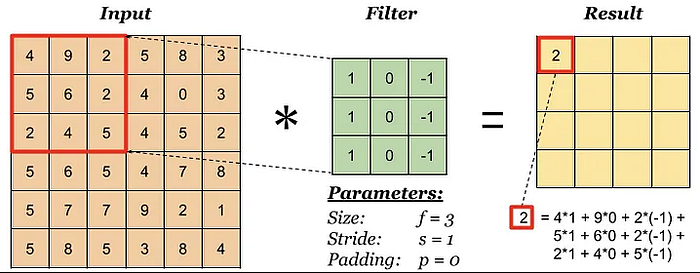
Let’s walk through an example of how a filter(kernel) produces a feature map:
First Position (Top-Left Corner)
Overlay the filter on the top-left corner of the image:
# Input Image Filter
1 2 3 1 0
4 5 6 0 1
7 8 9# multiply and sum:
(1*1) + (2*0) + (4*0) + (5*1) = 1 + 0 + 0 + 5 = 6So, the first number in our feature map is 6.
Slide to the Right
Move the filter one square to the right:
1 2 3 1 0
4 5 6 -> 0 1
7 8 9(2*1) + (3*0) + (5*0) + (6*1) = 2 + 0 + 0 + 6 = 8So, the next number in our feature map is 8
Repeat this for the entire image.
The behavior of the convolutional layer is based on the following hyperparameters:
- Filter/Kernel size:
It determines the size of the sliding window, preferably the size of the kernel is small.
- Suppose we have 32 filters, each of size 3x3x3 (height x width x channels). These filters will slide over the input image.
2. Strides:
The stride parameter determines the number of pixels by which the filter is moved across the image.
When stride = 1, it moves one pixel at a time. Typically stride is set to 1 to ensure no location is missed in an image. A larger stride creates a smaller output dimension, effectively downsampling the image.
Learn more about the Strides
3. Padding:
Padding involves adding extra pixels around the borders of the image. By applying padding kernel fully filter every position, ensure that even corners or borders are processed properly.
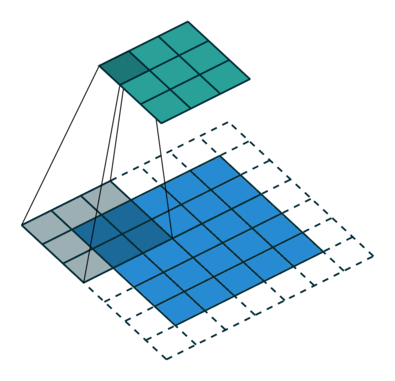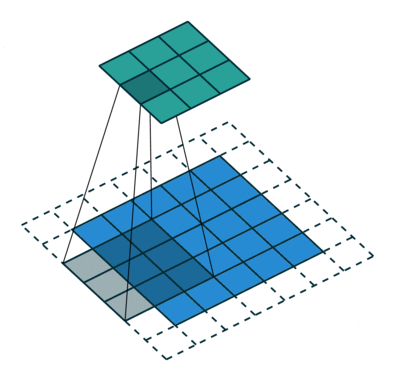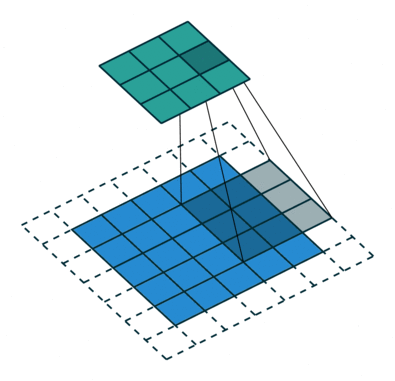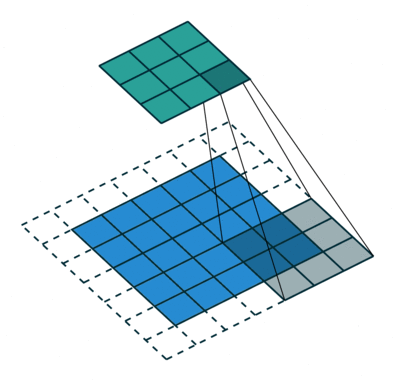
Types of Padding:
→ Valid Padding
→ Same Padding
Learn more about Padding
4. Number of filters/Depth of layer:
The number of filters in a convolutional layer depends on the number of patterns and features that the layer will identify.
The output size of the convoluted layer is determined by several factors, including the input size, kernel size, stride, and padding. The formula to calculate the output size:
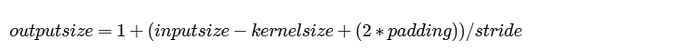
This formula takes input size (I), filter size (K), padding (P), and stride (S).
Suppose; we use a kernel with dimensions of 3x3 pixels, a stride of 1, and no padding (padding of 0).
we get;
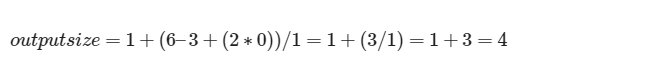
So, the output convoluted image is 4 x 4 pixels.
5. Activation Function:
Activation functions are used in the hidden layers of the network to introduce non-linearity into the network. The most commonly used activation function in CNNs is the ReLU (Rectified Linear Unit) activation function.
Pooling Layer:
After the convolutional layer, there comes the pooling layer. Pooling is also known as sub-sampling and downsampling. It reduces the size of the dimensionality while retaining essential information or features.
→ Pooling is like compressing an image file, you lose some details but essential features or information are still there.
Types Of Pooling:
→ Max Pooling
→ Average Pooling
→ Sum Pooling

Fully Connected Layer:
A fully connected layer usually known as the Dense layer, typically appears at the end of CNN architecture.
We flattened our matrix into a vector and fed it into the Fully connected neural network.
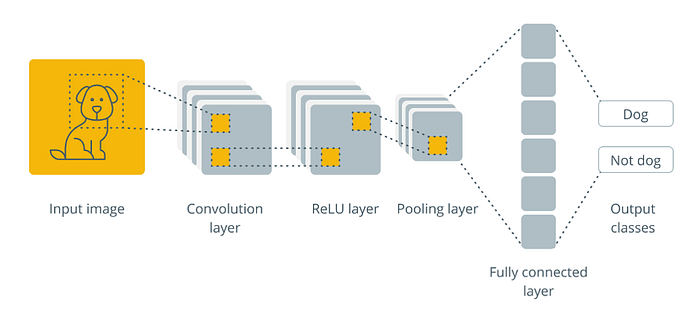
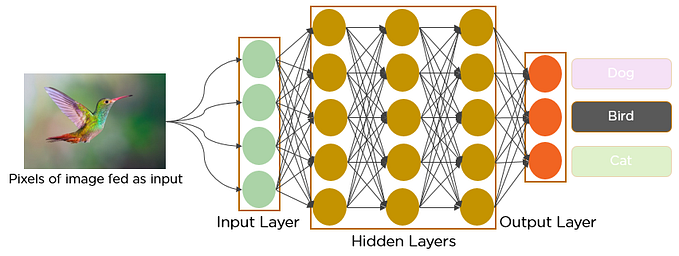
In the above image, the feature map matrix will be converted as vectors (x1, x2, x3, …). With the fully connected layers, we combined these features to create a model. Finally, we have an activation function such as softmax or sigmoid to classify the outputs as cat, dog, car, robot, etc.
Summary
- Provide input image into convolution layer
- Choose parameters, apply filters with strides, and padding if required. Perform convolution on the image and apply ReLU activation to the matrix.
- Perform pooling to reduce dimensionality size
- Add as many convolutional layers until satisfied
- Flatten the output and feed into a fully connected layer (Dense Layer)
- Output the class using an activation function and classify images.
For practical implementation, visit Colab Notebook and explore CNN Architecture with the CIFAR10 dataset.
If you have any questions or suggestions, please feel free to ask or reach out on LinkedIn
If enjoyed this piece, please give it a clap 👏 and share it with other fellows who might find it useful. I’ll try to bring more Data Science and AI articles.
Happy Learning :)